
4. října 2024
Neuronové sítě: Jak umělá inteligence napodobuje lidský mozek
Co se dočtete
Neuronové sítě jsou fascinující oblastí umělé inteligence, která se snaží napodobit způsob, jakým funguje lidský mozek. Samotné fungování neuronové sítě je v podstatě obří matematický příklad. To zní pravda trochu složitě. Pokusíme se proto fungování neuronových sítích vysvětlit na několika jednoduchých příkladech. A následně zabrousíme i do hlubších vod tohoto fenoménu.
Mozek jako inspirace
Neuronové sítě si berou inspiraci ve struktuře lidského mozku, který obsahuje téměř 100 miliard neuronů – buněk, které spolu komunikují prostřednictvím elektrických signálů. Neuron v mozku obdrží signál od jiného neuronu, zpracuje ho a rozhodne, jestli tento signál „předá“ dál. Podobně neuronové sítě používají matematické modely, které tento proces napodobují.
Umělé neuronové sítě pro jednodušší úlohy obvykle obsahují stovky až tisíce neuronů. Díky pokroku ve výpočetní technice však dnes dokážeme na složitější problémy nasadit a trénovat neuronové sítě, které mají miliony, a v poslední době dokonce miliardy neuronů.
Běžné programování vs. neuronové sítě
V konvenčním přístupu k programování říkáme počítači, co má dělat, a rozdělujeme velké problémy na mnoho malých, přesně definovaných úloh, které počítač může snadno provést. Naproti tomu v neuronové síti počítači neříkáme, jak má náš problém vyřešit. Místo toho se učí z pozorovaných dat a sám přichází na řešení daného problému.
Automatické učení z dat zní slibně. Až do roku 2006 jsme však nevěděli, jak neuronové sítě trénovat, aby překonaly běžné programování, s výjimkou několika specializovaných problémů. V roce 2006 to změnil objev tzv. hlubokých neuronových sítí. Tyto techniky jsou nyní známé jako tzv. hluboké učení (deep learning).
Analogie neuronových sítí
Představte si, že máte obrovskou skupinu detektivů, kteří se snaží vyřešit zločin. Každý detektiv má jen malý kousek informací a jejich úkolem je zjistit, jak se tento kousek hodí do celkového obrazu. Každý neuron („detektiv“) přijímá informace (vstupy), provádí na nich jednoduché výpočty a posílá výsledky dál (výstupy). Výstupy se pak stávají vstupy pro další neurony a tak dále. Všichni dohromady pak pracují na vyřešení zadání.
Příklad neuronové sítě – co je na obrázku?
Řekněme, že máme neuronovou síť, která se snaží rozpoznat obrázky zvířat. Na začátku síť dostane obrázek (např. kočky) a každý neuron v první vrstvě sítě se podívá na malý kousek tohoto obrázku. Některé neurony mohou být naprogramovány tak, aby hledaly určité vzory, jako jsou třeba linie nebo kruhy. Pokud jeden z neuronů „vidí“ něco, co vypadá jako linie, aktivuje se a pošle signál dalším neuronům. Tyto neurony pak mohou hledat složitější vzory, jako jsou třeba tvary obličeje. Celý tento proces se opakuje v několika vrstvách neuronů, dokud konečně poslední vrstva neuronů rozhodne, jestli na obrázku kočka je, nebo není.
Princip vah a učení
Každý neuron v síti je spojen s mnoha dalšími neurony a každé spojení má určitou váhu – tzn. relevanci pro ostatní neurony. Váhy se mění v průběhu tréninku sítě, což je proces, kdy se síť „učí“ rozpoznávat vzory v datech. Trénink neuronové sítě zahrnuje mnoho iterací (opakování postupu s cílem se přiblížit požadovanému stavu) a úprav vah. Cílem je najít takové nastavení vah, které umožní síti co nejpřesněji a nejefektivněji rozpoznávat vzory v datech.
Efektivita je klíčová
Efektivitu neuronové sítě si pak můžete představit tak, že na začátku stojíte před problémem - nevíte, jakou podobu neuronové sítě, tzn. kolik neuronů rozdělených do kolika vrstev, potřebujete pro rozpoznání obrázku kočky. Zpočátku může síť potřebovat pro správné rozhodnutí tisíce neuronů v desítkách vrstev, a tím pádem i vysoký výpočetní výkon. Postupným opakováním si ale neuronová síť kalibruje váhy (sílu vazeb) mezi určitými neurony, a tím může některé neurony i celé vrstvy z rozhodování začít vylučovat, protože je pro správné rozhodnutí nepotřebuje. Z tisíců neuronů tak mohou zbýt po efektivním učícím procesu jen stovky a celý proces rozpoznávání obrázku se tak zjednoduší a zrychlí.
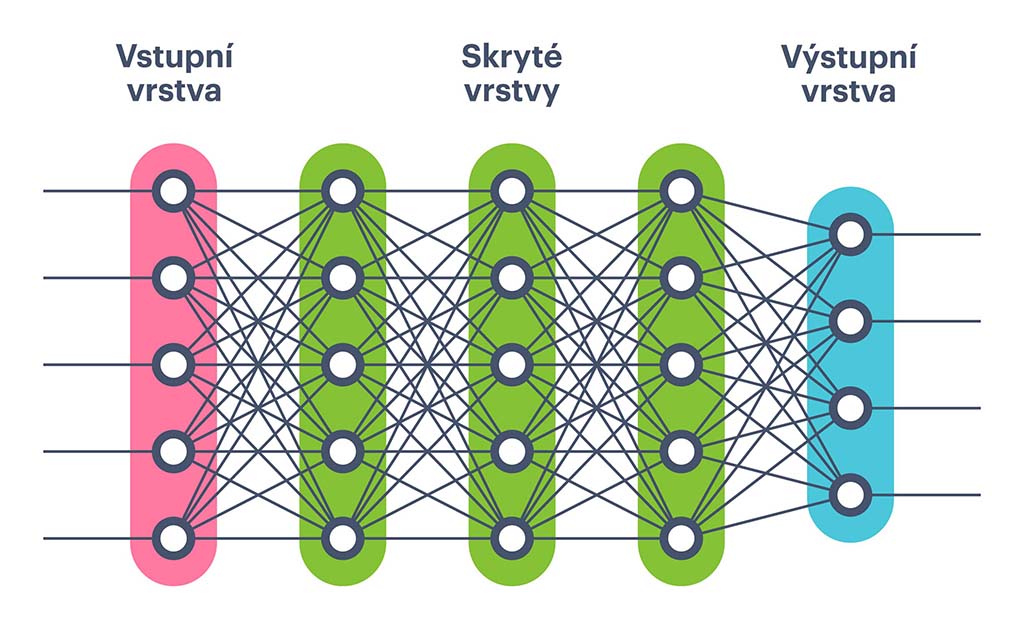
Základní struktura neuronové sítě
Neuronové sítě se skládají z vrstev neuronů, které jsou vzájemně propojeny. Nahodilé rozmístění neuronů by se totiž těžko udržovalo v paměti a operace na nich by byly pomalé. Proto je nutné síť uspořádat. Nejjednodušším uspořádáním jsou právě vrstvy (viz obrázek níže). Každý neuron z jedné vrstvy má dendrity (spojení) se všemi neurony z vrstvy předešlé. Síla jednotlivých spojení se kalibruje tréninkem sítě, během kterého určité vazby sílí, zatímco jiné slábnou. Neuronové sítě obvykle obsahují tři hlavní typy vrstev:
Vstupní vrstva: Přijímá data, např. pixelové hodnoty obrázku.
Skryté vrstvy: Provádějí většinu zpracování dat. Množství skrytých vrstev a neuronů v každé vrstvě může být různé a ovlivňuje schopnost sítě učit se složité vzory.
Výstupní vrstva: Generuje konečný výstup, například klasifikaci obrázku.
Sestavte si neuronovou síť
Princip a trénování neuronové sítě skvěle přibližuje stránka playground.tensorflow.org, kde si můžete vybrat jednoduchý problém k řešení, sestavit si neuronovou síť (počet neuronů a vrstev) a sledovat, jestli a jak rychle vaše neuronová síť problém vyřeší.
Proces trénování neuronové sítě
Trénink neuronové sítě zahrnuje několik klíčových kroků:
-
Příprava dat: Než začneme trénovat neuronovou síť, je důležité mít kvalitní a dobře strukturovaná data. Tato data se často dělí na tréninkovou, validační a testovací sadu. Tréninková sada se používá k učení, validační sada k ladění a testovací sada k hodnocení výkonu modelu.
-
Forward propagation (dopředná propagace): Při tomto kroku vstupní data procházejí sítí. Každý neuron zpracovává vstupy, aplikuje váhy, aktivační funkci a generuje výstup. Tento proces pokračuje až do výstupní vrstvy, kde se získá konečný výstup sítě.
-
Ztrátová funkce: Po dopředné propagaci se porovná výstup sítě s očekávaným výstupem (označovaným jako „ground truth“). Ztrátová funkce měří, jak dobře síť fungovala. Například v úloze klasifikace může být použita křížová entropie jako ztrátová funkce, která vyjadřuje rozdíl mezi skutečnými a predikovanými pravděpodobnostmi.
-
Backward propagation (zpětná propagace): Tento krok zahrnuje úpravu vah neuronů na základě chyby, kterou síť udělala. Zpětná propagace využívá gradientní sestup, což je optimalizační algoritmus, který minimalizuje ztrátovou funkci. V podstatě se vypočítá gradient ztrátové funkce vzhledem k váhám a tyto váhy se upraví v opačném směru gradientu.
-
Iterace: Proces dopředné a zpětné propagace se opakuje po mnoho cyklů dokud se výkon sítě nezlepší nebo nedosáhne určité úrovně přesnosti.
Neuronové sítě, internet a nabídka pro vás
Pro trénink neuronových sítí jsou nezbytná data. Internet je tak klíčovým zdrojem informací pro jejich vývoj. A ruku na srdce, ani my lidé se bez něj neobejdeme. Můžete mít na své adrese výhodnější internet? Podívejte se, jaké internetové tarify získáte u nás. Stačí zadat adresu a ihned online uvidíte dostupnou nabídku.